
#9. RAG-based Member Retrieval
Build a recommendation system with semantic search (embeddings) that can return members, products, books, movies etc most related to the search intent of your query (without using exact keywords).
Forwarded this email? Subscribe here for more ✨
Welcome to the 9th edition of the 100 GenAI MVPs newsletter, a journey all about shipping 100 happy and helpful GenAI solutions, and how to build them! 🚀👩💻✨ Together, we have built a robot panda you can chat with (🏆 award winner), a mental health MVP for highlighting unhelpful thinking patterns in journal entries, and many more!
Hellooo AI Alchemists! ✨🤖🧪
This is a really special edition of Fairylights, because this GenAI project is going to be used by the Build Club community (my second home), to help members discover and connect with like-minded AI builders.
🏆 This project won first place in a competition where 5 AI builders competed to build a member retrieval system on top of a member database (AirTable), in 2 weeks.
I say competed, but we all just geeked out and admired each others work 🥰

This member retrieval solution applies to ecommerce product recommendations too. In this deep dive, I’ll show you how I solved most of the discovery and connection problems without using AI at all. Then how to implement semantic search using embeddings to make searching for members/products extra helpful and sparkly ✨
Are you ready!??
Let’s get building!
(this is a monster deep dive, bookmark for future reference)
— Becca 💖

📣 A few quick announcements 🥳
100 Subscriber Milestone! Thank you SO much for your support at the very start of this journey, you magical people you 😭🥰
+2 paid subscribers! This is so sweet because none of the content is paywalled. THANK YOU, it is very much appreciated 💖
Interviewed in Balance The Grind: Interviews on work, life & balance with CEOs, startup founders, business leaders, entrepreneurs, freelancers and more (70,000+ readership). Honoured to be featured (upcoming).
AI Workshop! On Thursday, Apr 11 at 6:00pm-8:00pm, I’ll be at the University of Technology Sydney teaching a workshop on how to build a YouTube summariser app that sends you a monthly roundup email, as part of the Sydney AI Happy Hour meetup. RSVP here if you’re local! 👩💻
🤿 How to build a member retrieval RAG app
I’m SO excited about this deep dive, learning how to build a RAG app is something that has been on my AI project bucket list for some time now.
This deep dive starts with an overview of building a member/product retrieval system without AI to start with. Then it goes deep into how you can implement semantic search with embeddings (using accessible, non-jargonified language and examples).
Problem to solve
The main problems that this member retrieval solution needed to solve, was to make it as easy as possible for Builders to collaborate and discover what each other are working on.
We were given access to an AirTable database containing member onboarding data, where members describe what their areas of expertise are when they first join.
When looking at the onboarding data, I realised that a member retrieval system built on top of that wouldn’t work, because of how quickly it would go out of date.
For example, OpenAI’s Sora video generation model was released the same week as this competition, so there’d be no way to use past onboarding data to find people who are playing with it right now.
Instead, I requested access to our build update data instead to create a more effective solution. Build updates are little progress updates on projects we are working on. We can submit those as often as we like.

Solution without AI
I spent the first 1.5 out of 2 weeks of this competition building a solution that didn’t use AI at all. Instead, I stuck two post-it notes to my computer to represent the two key problems to solve:
🔑 Discover what each other are working on?
🔑 Collaborate with each other?
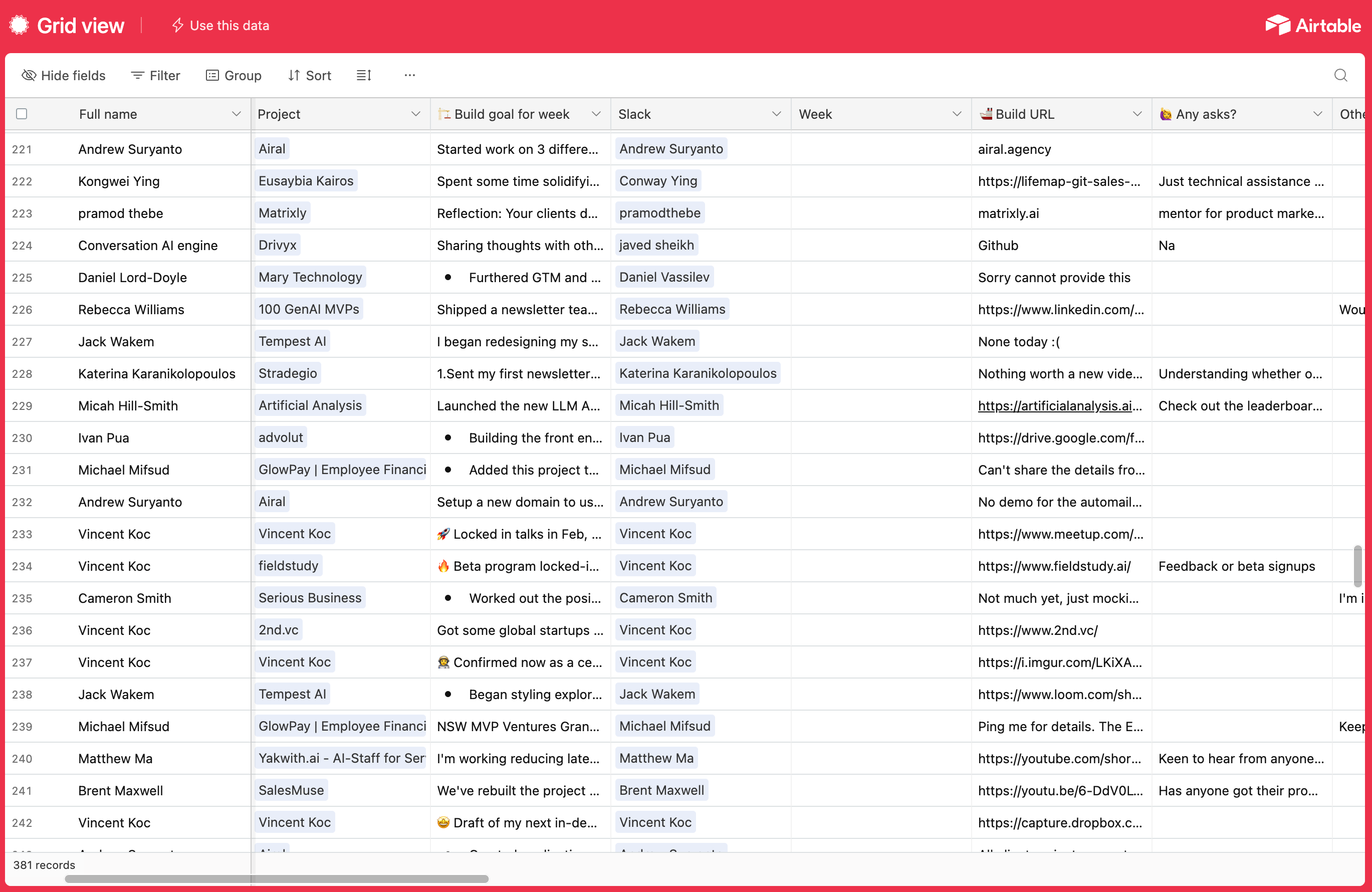
1. Retrieve data from AirTable
I started by retrieving all of the data I needed from AirTable using the following code:
import requests
def get_members(view_name=None):
url, headers = "https://api.airtable.com/v0/appnc2IWGpsHNfTvt/Members", {"Authorization": "Bearer <YOUR ACCESS TOKEN>"}
params = {} if view_name is None else {"view": view_name}
members = []
while True:
res = requests.get(url, headers=headers, params=params).json()
members += res.get('records', [])
if 'offset' not in res: break
params['offset'] = res['offset']
return members
if __name__ == "__main__":
members = get_members("Accepted only")
print(f"First member: {members[0]}") # => First member object
print(f"How many members? {len(members)}") # => 456To make this work for your AirTable:
Change the URL to the one that matches your AirTable database.
Change the access token to your personal access token.
Change the name of the method from “get_members”, to “get_your_data”.
When using the method, if you want to get data from a specific view, provide a view name as an argument, otherwise it’ll retrieve all rows.
I used this for retrieving the build updates from a different table too.
A couple of things to watch out for when retrieving data from AirTable:
Image links expire after 2 hours, so you need to save them somewhere.
If there are more than 100 records, AirTable only returns the 1st 100 so you need to implement pagination to get all of them. The code I wrote above does that for you.
2. Decide what data to keep and exclude
Then I decided what data to keep and what to exclude. The data I excluded included confidential or sensitive data like phone numbers and emails, and anything not directly relevant to helping members discover and connect with each other.
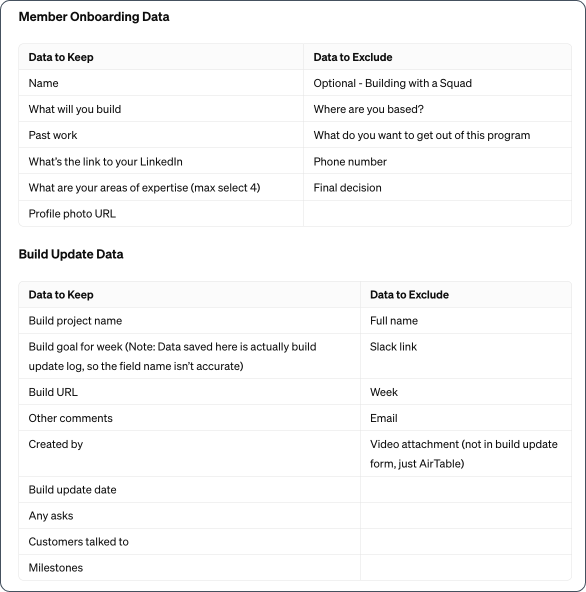
3. Organise data in a way that makes sense for your project
After deciding which data to keep and exclude, I reorganised it into a schema that made most sense for this project. I wanted to make it easy to see which build updates belonged to which projects, and which projects belonged to which members.
This is what I came up with:
# One Member object
{
"id": "<MEMBER ID>",
"profile_picture": "<PROFILE PHOTO URL",
"name": "<MEMBER NAME>",
"building": "<CURRENTLY BUILDING>",
"past_work": "<PAST WORK>",
"linkedin_url": "<LINKEDIN URL>",
"areas_of_expertise": ["<AREA_ONE>", "<AREA_TWO">],
"projects": [
{
"project_name": "<PROJECT NAME>",
"project_description": "<PRODUCT DESCRIPTION>",
"build_updates": [
"date": "<DATE>",
"build_update": "<BUILD UPDATE>",
"asks": "<ANY ASKS>",
]
}
]
}4. I saved data in a simple file instead of a vector database
Because there are less than 1000 members, I decided to save all of the Build Club members to a simple members variable containing a list of member objects in a file called members.py, like this:
# members.py
members = [{<MEMBER_ONE>}, {<MEMBER_TWO>}, {<MEMBER_THREE>}] ...I also added logic to make sure to save only new members whenever the list of members retrieved from AirTable was longer than the list of saved members.
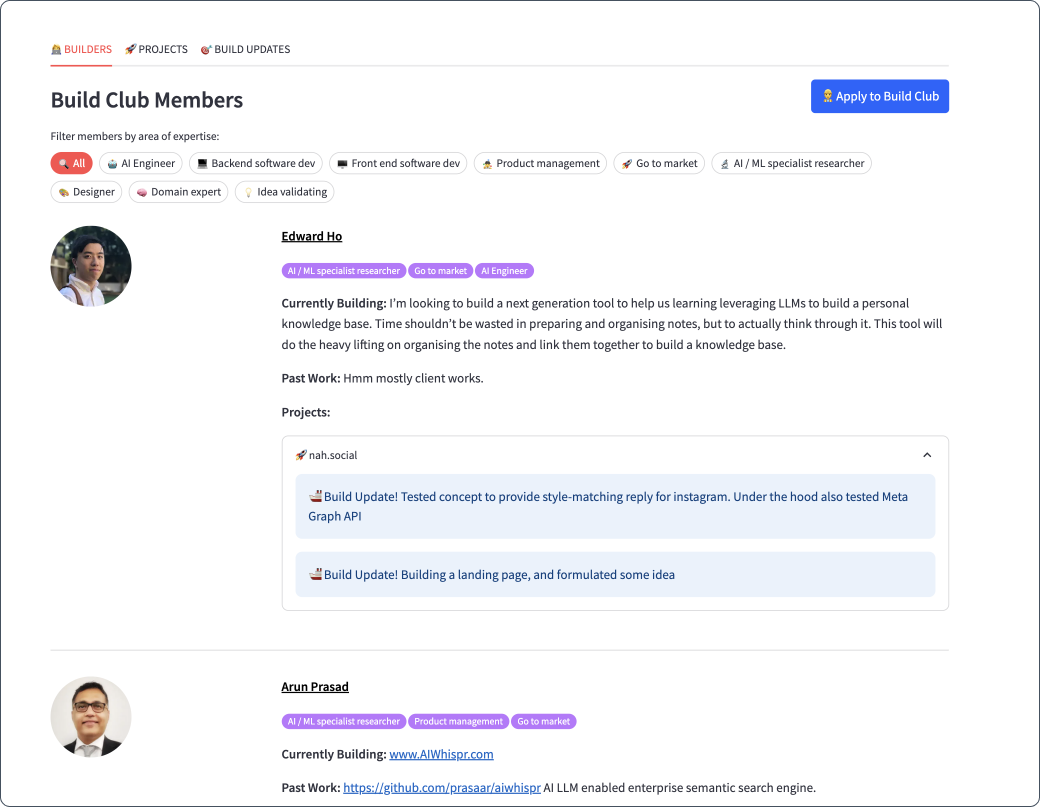
5. Display members (pagination, filter chips, linkedIn links)
With the data nicely organised, it was easy to display members so that you can see all of the projects and build updates associated with them.
Each members name links to their LinkedIn profile, to make it as easy as possible for builders to connect with each other.
We can also filter members by areas of expertise, so if we need help with developing software, designing user experiences, validating ideas or going to market etc, we can find people who have self-identified as able to help in these areas.
What’s missing?
After all of the above was done, it was much easier to see where AI could add the most value. It’s easy to browse members, but it’s difficult to search for members who fit qualitative criteria.
🚫 This non-AI solution makes it difficult to retrieve all members working in a specific industry like Law, or who are experts in old as well as emerging AI technologies, like Retrieval Augmented generation or Sona Video Generation (released very recently).
I tried to solve this without AI too using keyword search, but it required writing keyword stuffed queries which accounted for acronyms, expanded versions of acronyms and alternative ways of saying the same thing.
It also involved trying to remove filler words like "a", "the", "an", "with", "in" etc from our query, but even then we were left with a lot of words that don't match the intent of our query.
✨ So the major value add AI had in this project was semantic search. The ability to retrieve members who most closely matched the intent of our search query, even if we only included one keyword like RAG, instead of Retrieval Augmented Generation.
Heres’s how you can implement semantic search for better member or product retrieval:
How to implement semantic search with AI embeddings
Semantic search is where the search engine knows what you’re looking for, even if you don’t say the exact words.
🕯️ Semantic search illustrated with candles
Imagine you're looking for candles that have a calming effect. You type "calming candles" into a search engine. A regular search engine might give you results that directly match those words, like products or articles containing the exact keywords "Calming”, “Candles".
With semantic search, the search engine is able to understand the intent behind your search. It knows you’re looking for candles that can help you relax. So, it gives you results that include not just candles labeled as “calming”, but also candles with scents commonly associated with relaxation, like lavender, chamomile or other relaxing aromas. It might also surface articles about the benefits of aromatherapy candles for relaxation.
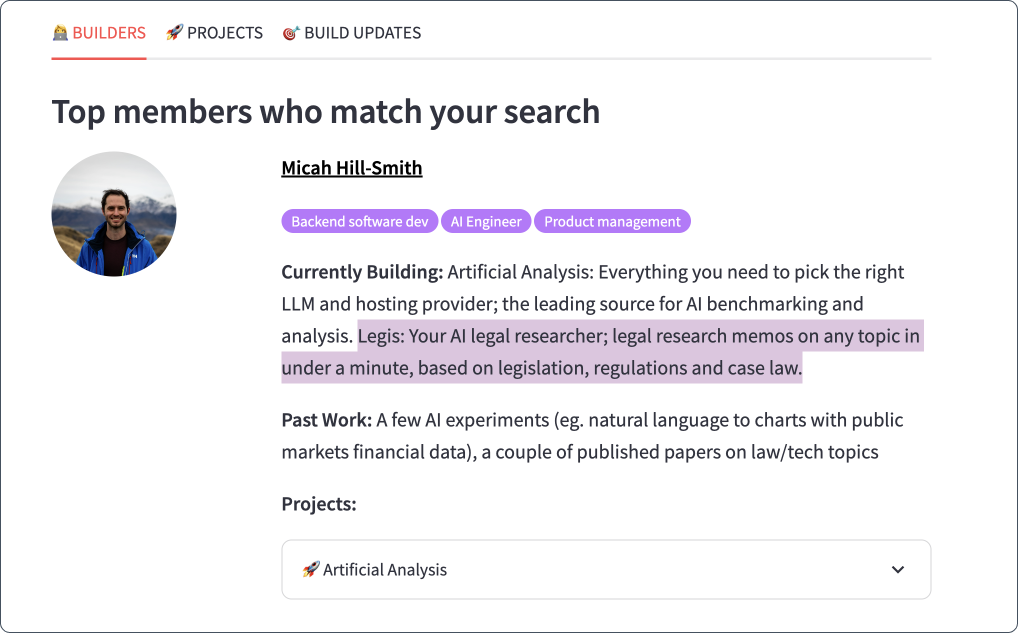
👩🏻💼 Semantic search for member retrieval - AI legal help
In the context of this member retrieval system, you might be a build club member who would like to find someone to help you with legal issues related to your AI project. So you type “legal help for AI” into the member retrieval search bar.

In a traditional keyword search, it breaks your query into individual words: “legal”, “help”, “for” and “AI”. It then looks for members who have those exact words in their onboarding, project and build update data.
Then it will return a list of members who have used any of those exact keywords in their onboarding data or build updates. So you might see members who mentioned a legal book they read, or someone who asked for “help”, but isn’t able to provide legal help specifically for AI projects.
🙈
However with semantic search, it is able to provide much more valuable results because it understands the context of your query.
It knows that "legal help for AI" means you're looking for someone with legal expertise related to AI. So, it gives you results that include members who are lawyers with experience in AI, or legal advisors who specialise in technology. It retrieves members most related to the intent of your query, even if none of the keywords in your query are directly mentioned in a members profile. E.g. you asked for “legal help” and get back “lawyers”.
How to implement semantic search (and how does it work)?
To implement semantic search for the query “Who can help me build RAG systems”, you need some kind of an embeddings model. For this project, I used OpenAI’s embeddings model.
💡 What are embeddings?
Embeddings are long nested lists of numbers (high-dimensional vectors) that capture the semantic meaning of a text. The numbers represent different aspects of a words meaning, including its grammatical and conceptual properties. They also capture relationships between words and phrases, including synonyms, antonyms and associations. The type of meaning captured depends on the training data and the model used.
⚙️ How to create an embedding?
Creating an embedding with OpenAI’s embeddings model is really easy, this is all there is to it:
from openai import OpenAI
def create_embedding(data):
client = OpenAI(api_key=st.secrets["openai"]["api_key"])
response = client.embeddings.create(
input=data,
model="text-embedding-3-small"
)
return response.data[0].embeddingThe embedding that is returned looks like this:
[
0.013539750128984451,
-0.016625553369522095,
-0.0022848329972475767,
0.00843872781842947,
-0.04238256812095642,
-0.027882440015673637,
0.020907893776893616,
-0.00410128477960825,
-0.009737599641084671,
-0.0036899757105857134,
0.049152445048093796,
-0.01057202648371458,
-0.01463395170867443,
-0.024843867868185043,
0.02125426009297371,
-0.016035158187150955,
-0.03658881410956383,
-0.04559432342648506,
# ... A very long list that requires a lot of scrolling to get through📝 What to create embeddings of?
In a RAG system, you need to create embeddings of anything you want to be findable through search, like members or products, as well as the query used to search for things.
Embeddings can be created from words, phrases, sentences, or even entire documents. For this member retrieval system, I created an embeddings for members and their build updates.
Create an embedding for your search query
Every time a user enters a new search query, it needs to be converted into an embedding before it can be used to retrieve related members or products.
query_embedding = create_embedding("Who can help me build RAG systems")Prior to the first search query, you need to create embeddings for anything you want to retrieve via semantic search. I chose to create embeddings for members and build updates.
This increases the quality of search results in two ways:
Members can search for builders based on their onboarding data alone, who self-identified as an expert in a given area. If projects and build updates were included, that would be diluted.
Members can search for builders who have recently shipped updates related to a specific area or project. Many members who have gone through the onboarding process have not started projects or shipped updates within build club, so this increases the chances that you will be connected to a builder who is active right now.
Here is how to create embeddings for both members and build updates:
Create an embedding to represent each member
This was the original object representation of each member that we created through the non-ai solution.
# One Member object
{
"id": "<MEMBER ID>",
"profile_picture": "<PROFILE PHOTO URL",
"name": "<MEMBER NAME>",
"building": "<CURRENTLY BUILDING>",
"past_work": "<PAST WORK>",
"linkedin_url": "<LINKEDIN URL>",
"areas_of_expertise": ["<AREA_ONE>", "<AREA_TWO">],
"projects": [
{
"project_name": "<PROJECT NAME>",
"project_description": "<PRODUCT DESCRIPTION>",
"build_updates": [
"date": "<DATE>",
"build_update": "<BUILD UPDATE>",
"asks": "<ANY ASKS>",
]
}
]
}To create an embedding for each member based, I first created a text representation of each member based on their onboarding data only.
I could created an embedding from the full member object, but I didn’t want to include things like their profile picture, id, or linkedIn URL.
member_text_representation = """
Name: Rebecca Williams
Building: 1. An IOT bear that you can have a back and forth convo with, powered by GPT, 2. Natural language database querier (write what data you want in english and it'll generate and run SQL for you). 3. A journal analyser (guiding you through mental health skills based on what comes up in your journal entry).
Past work: 1. A Harry Potter chatbot that lets you chat to different Potter characters. They also have character appropriate emojis! Link: https://www.fairylights.ai/chatty_potter/ 2. A cognitive distortion checker. Write a stream of consciousness journal entry and get back a list of unhelpful thinking patterns (cognitive distortions) that are present so you can focus on reframing them Link: https://fairylights-thought-checker.streamlit.app/#thought-checker
"""I turned the text representation into an embedding:
member_embedding = create_embedding(member_text_representation)Then I added that embedding to the original member object like this:
{
"id": "<MEMBER ID>",
.... other keys
"member_embedding": member_embedding
}Create an embedding to represent each build update
I also turned every single build update into an embedding too. This is an example of what a member object looked like after completing this process:
# One Member object
{
"id": "<MEMBER ID>",
"profile_picture": "<PROFILE PHOTO URL",
"name": "<MEMBER NAME>",
"building": "<CURRENTLY BUILDING>",
"past_work": "<PAST WORK>",
"linkedin_url": "<LINKEDIN URL>",
"areas_of_expertise": ["<AREA_ONE>", "<AREA_TWO">],
"member_embedding": [
0.013539750128984451,
-0.016625553369522095,
... ]
"projects": [
{
"project_name": "<PROJECT NAME>",
"project_description": "<PRODUCT DESCRIPTION>",
"build_updates": [
[
"date": "<DATE>",
"build_update": "<BUILD UPDATE>",
"asks": "<ANY ASKS>",
"build_update_embedding": [
0.013539750128984451,
-0.016625553369522095,
... ],
]
]
}
]
}📝 Using embeddings to search for relevant members
Now that we have embeddings for our search query and members, we can perform semantic search by ranking members based on how similar their embeddings are to the search query embedding.
To illustrate, imagine you have the following search query:
Feline = [0.88, 0.08]
And the following word embeddings:
Train = [0.1, 0.9…]
Cat = [0.9, 0.1…]
Dog = [0.08, 0.15…]
Lion = [0.85, 0.05…]
Using a semantic similarity algorithm designed for measuring how closely embeddings are related (cosine similarity is the most typical algorithm), we would get back the following results:
Cat = [0.9, 0.1…]
Lion = [0.85, 0.05…]
Dog = [0.08, 0.15…]
Train = [0.1, 0.9…]
Cat, and Lion are closer in semantic meaning to “Feline” than Dog or Train. This process of organising data based on how similar it is to the search query is called Ranking.
Compare embeddings with a cosine similarity algorithm
This is how you can implement the cosine similarity algorithm for comparing one embedding (e.g. search query) with another (e.g. member or product):
from sklearn.metrics.pairwise import cosine_similarity
def cosine_similarity(vec1, vec2):
return np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))Overall, semantic search with OpenAI embeddings aims to provide more accurate and relevant search results by focusing on the meaning behind the words rather than just the words themselves.
Things to watch out for when implementing semantic search
Semantic search will always return results even if there are no relevant results. So you need to implement a check that there are relevant results first.
You will also need to implement an ejection step so that if there are relevant results, only relevant results are returned. In the example above, we only want “Cat” and “Lion”, not “Dog” and “Train”. Otherwise your searchers can scroll right down to irrelevant results which can be confusing.
Next Steps
I built this member retrieval system in 2 weeks for a competition. While it was helpful enough to be voted the winner, there are still some things I’d like to implement to make it even more awesome:
Automatically generate project summaries based on build update history.
Summarise the last weeks worth of build updates.
After a certain number of build updates have been shipped, update the “currently building” profile information to reflect what members are shipping.
Here is a demo of the member retrieval system in action (my competition submission video):
You can try out the live version here:
Build Club’s Member Discovery Chatbot.
Let me know what you want to see more of 💖
A few wonderful subscribers have told me that the reason they love this 100 GenAI MVP deep dive series is because:
They don’t have enough time outside of their day job to build stuff like this, so they appreciate the exposure to how to do it. It saves them time when they want to experiment too.
They appreciate the creativity of the problems being solved with AI.
Reading this makes them think about ways they can solve their own work problems.
I appreciate this feedback SO much. It’s much better writing with specific people in mind.
So if you get a chance, please hit reply and let me know your thoughts:
Why do you read Fairylights?
What are your favourite topics?
What would you most like to see in the future?
Your feedback will help me plan even better GenAI MVPs and deep dives for you.
Thank you,
You’re the best!
— Becca 💖
Moar GenAI Projects! 🤖🧪✨
🎁 Here are some more projects to check out if you loved this one!
#8. ChatGPT-Powered Robot Panda

Helloooo AI Alchemists! ✨🤖🧪 Late last year, my friend Stan and I won the People’s Choice Award at Fishburner’s Young Entrepreneur Pitch night, where I demo’d chatting with the panda on stage in front of 200+ founders and entrepreneurs 🐼🎤 The CEO of Fishburners said:
#7. Create a lip-syncing character that responds to your messages by talking!

Helloooo AI Alchemists!!! 🤖🧪 Ever since sharing this project live on LinkedIn, I have gotten a TON of requests to make lip-syncing chatty avatars for a wide range of use-cases. This is incredibly popular, and there is a crazy amount of potential for extending and monetising this.
#2. Analyse a journal entry for unhelpful thinking patterns with ChatGPT's function calling 🤯

Helloooo AI Alchemists! ✨🤖🧪 Last weekend, I built a program that I’ve personally wished existed for years. It’s solved a real pain point for me, and I’m so grateful it was even possible. Not only was it possible, but it was easy. Crazy easy. This is it: