
#5. Ask questions about your database tables in plain english (ChatGPT function calling)
Upload all of your databases as CSV files and ask questions in plain english. This program will auto-generate and execute SQL statements to retrieve data needed to answer the question!

Helloooo AI Alchemists! 🤖🧪
Happy new year!
I hope you all had a chance to recharge and get energised by all of your wins last year.
I’m SO excited to share this magical ChatGPT use-case I built with you. It’s a game changer for helping business analysts and founders get insight from their data just by asking questions in plain english.
Problems this use-case solves
I got the idea for this GenAI solution during a conversation with a founder who specialises in collecting data about their industry, including companies, products and investments made etc etc.
Their biggest pain point was trying to leverage their data to answer questions about their industry when various investors, stakeholders and c-suite execs would ask them ad-hoc. It was difficult because:
❌ The data was spread across multiple spreadsheets and was difficult to find, and
❌ Writing queries to retrieve data based on complex questions required time and expertise. I thought that GenAI could be used to solve this.
This GenAI solution solves both of these and then some:
✅ It helps you find data you need faster, especially when it's housed across many different spreadsheets/databases.
✅ No need for expertise in writing SQL queries for complex queries like join tables. Just ask your questions as a human.
✅ Removes bottlenecks, e.g. if you're a business analyst and you want quick insights, you don't have to wait for a sys-admin to get the data for you.
Here’s a demo of how it works:
You can try it out for yourself here (you need to provide your own OpenAI API key).

How to use this
To use this program, you can upload or drag and drop your CSV files as the first step.
I initially planned to let people connect to their own database, like MySQL/PostgreSQL by entering their database connection details, but decided against this for security reasons, so you have to export your databases to CSV files and upload each time you want to ask questions.
Once you’ve uploaded the files, you can browse through the tables and have a look at the data.
Then, you can ask any question in plain english, and it’ll auto-generate a SQL statement and then execute it against the data, then display the returned data needed to answer your question.
Other use-cases
Here are some specific examples where you could leverage and adapt this use-case:
🩺 Healthcare Data: Anonymised data around patient records, treatment details, and outcomes data. This would allow for queries like, 'Show the average recovery time for patients aged 60-70 with a specific condition’.
🏘️ Real-estate Market Trends: Use datasets on property sales, prices, demographics, and economic indicators. This can help answer questions like, 'What is the average price of three-bedroom houses in a specific area?'
🌳 Environmental Data Analysis: Use datasets related to climate, pollution levels, or wildlife populations. This might answer queries like, 'What has been the average air quality index in urban areas over the past five years?
🚂 Transportation and Logistics: Work with data related to public transportation usage, traffic patterns, and logistic operations. This can help in answering questions such as, 'What are the peak hours for public transportation usage in major cities?'

Testing this use-case
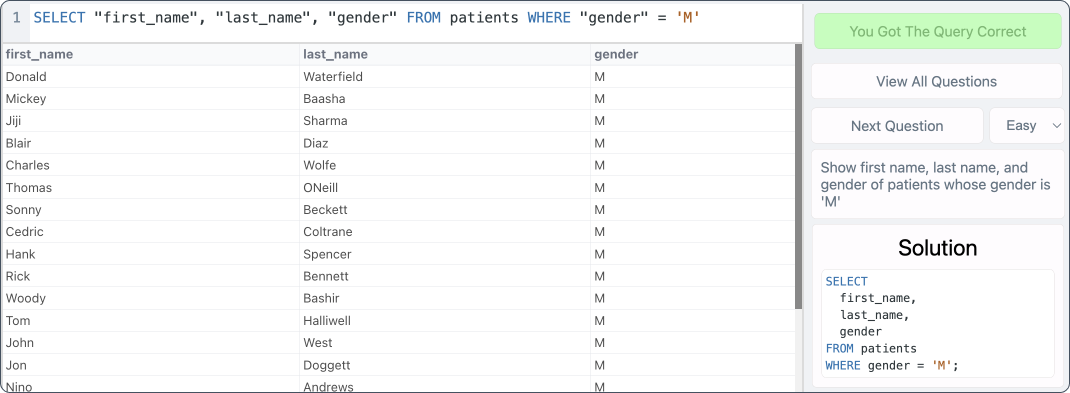
In order to thoroughly test this program, I found a website called Practice SQL that has 52 exercises for practicing querying four different tables in a database, including 16 easy exercises, 25 medium exercises and 11 hard exercises.
This GenAI program passed:
16/16 easy SQL exercises.
25/25 medium SQL exercises.
4/11 hard SQL exercises.
However, sometimes I had to run the same question twice to get a correct answer. The generated SQL statements are not always correct, and it struggles to answer complex queries that involve 2+ datasets, or require some kind of data transformation like creating a password based on a few different pieces of data.
How it works under the cover
How it works
1. Upload spreadsheets
Users can upload one or more CSV files through a user interface element provided by Streamlit (what I use to build front-ends suuuper quickly).
Each CSV file is converted to a Pandas DataFrame, which is a data structure like a table or spreadsheet with rows and columns. The advantage of using a Pandas DataFrame is that it can be easily integrated with other tools like a SQL database. This integration lets you run SQL queries on the data.
If column names in the spreadsheet have a space in them, I replace the spaces with underscores before converting to a DataFrame, because resulting SQL statements will see the space separated name as two separate columns instead of one.
Once the spreadsheets have been uploaded and converted to DataFrame’s, they are displayed on the page so the user can browse through their data.
2. Ask a question in plain english
A user can enter a question they want to ask about their data. I thought about adding a feature where people can generate question suggestions based on the uploaded data, but decided against that as it’s not core to this MVP.
3. Generate a SQL statement based on the question
This is the call I made to OpenAI’s GPT-3.5-Turbo model to convert a plain english question into a SQL statement:

I’m using the function calling capability of the API to return just the SQL statement as a string. Without the function call to specify the format of the output, the response is chatty.
There are two key parts to this prompt:
Pass in table schema and first row of data
Besides passing in the user question, I also passed in the schema of every table uploaded to the program, as well as the first row of content (not including long-text data).
I did this because when trying to retrieve a list of all male patients, the query tried searching for male patients based on the value “Male”. It wasn’t aware that the values in the gender column were saved as either “F” or “M”. So providing the first row of data solved those kinds of problems.
I excluded long-text data to reduce the chances of running out of room in the prompt (context window). My assumption was that long-text values won’t need to be handled as carefully as say date, gender, number or category-based values.
Generating dummy data based on table schemas with ChatGPT online version
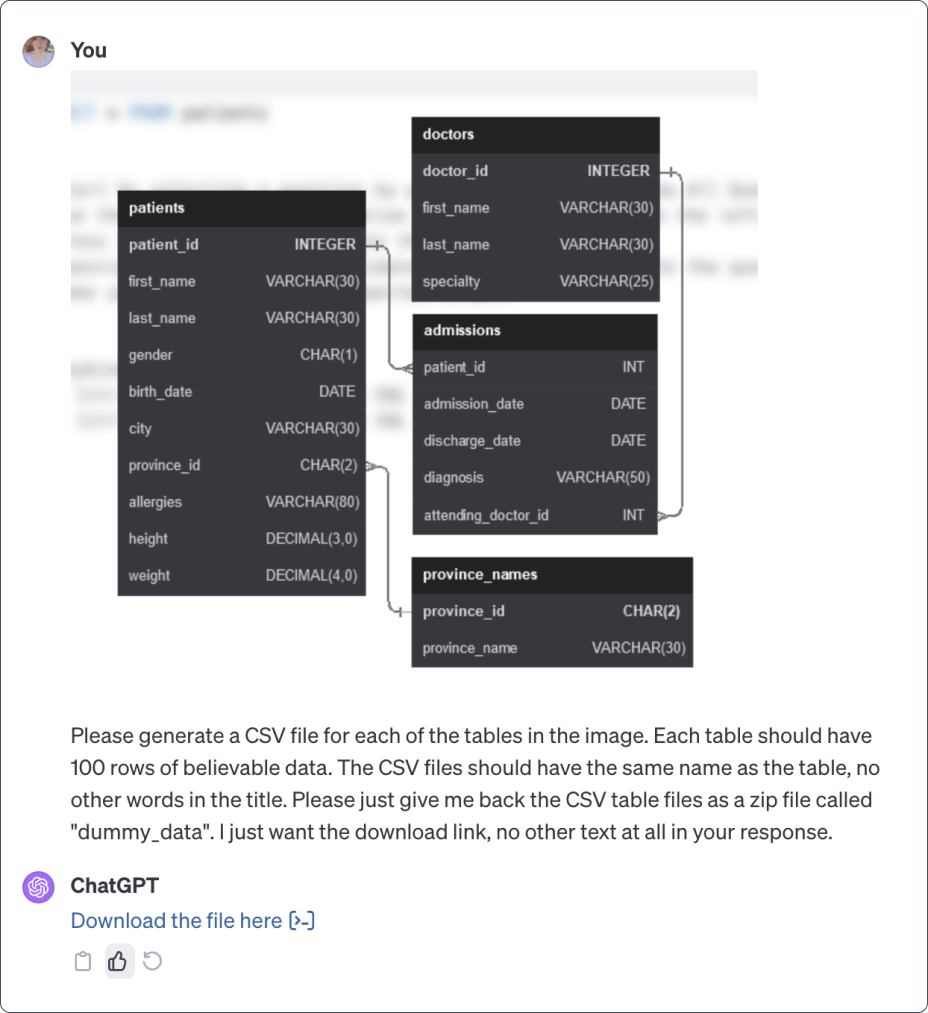
Because I wasn’t able to get access to the actual tables used for the exercises on the Practice SQL site, I was able to generate a set of dummy CSV files that followed the same schema, based on the provided table schemas shown in the image below:
Prompt modifications made to generate the tables of dummy data.
I had to replace the phrase “dummy data” in the above prompt to “believable data” because the original prompt filled the table with random words and phrases that were not at all related to the kind of data you’d expect to see in each column.
Instead of saying “Please just give me back the CSV table files”, I asked it to return a Zip file called “dummy_data” instead so I could download them all in a single click.
Handle dates for more accurate SQL statements
This is the main prompt used to generate SQL statements:
Read the question, schema and first row of the table carefully, then generate the simplest SQL statement you can. When handling date values, use strftime, use the CAST function to remove leading zeros and the DATE function to extract the date part from a datetime. Specify source name for columns in any join queries. Use the most appropriate columns for each query. Statements should be written in this order: 'SELECT [Columns to Select] FROM [Source Table(s)] WHERE [Conditions if needed] GROUP BY [Columns for Grouping if needed] HAVING [Conditions for Grouping if needed] ORDER BY [Columns for Sorting].'
It grew out of a process of trial and error, which highlights how important it is to have a range of scenarios to test each project against. The biggest cause of errors when testing this program was date-based values, for example:
Any questions that involved dates tended to throw errors until I modified the prompt to get GPT to handle date-based questions using strftime wherever possible. This method can accept a date in any format and force it into a specific format.
Telling GPT to use the CAST function to remove leading zeros from dates. I needed to do this to pass a Practice SQL exercise, but didn’t know why. So I googled (ChatGPT’d) why we should remove leading zeros, and it’s because it can mess up the order when sorting. So I updated my prompt to remove leading zeros from dates using the CAST function.
OpenAI call to process question and return SQL statement
This is the call I made to OpenAI’s GPT-3.5-Turbo model to convert a plain english question into a SQL statement:
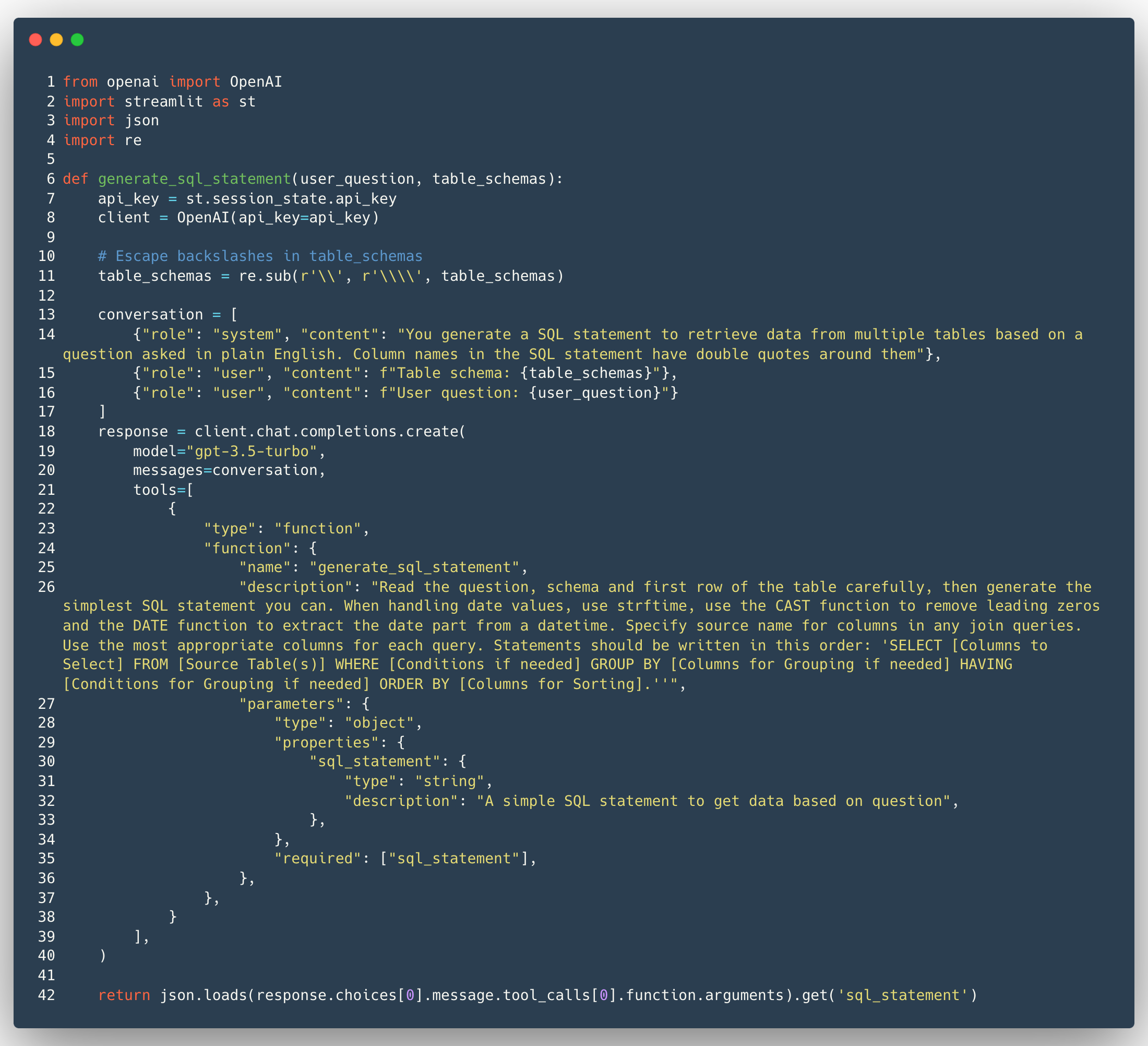
I’m using the function calling capability of the API to return just the SQL statement as a string. Without the function call to specify the format of the output, the response is chatty.
The key prompt in this call is:
Read the question, schema and first row of the table carefully, then generate the simplest SQL statement you can. When handling date values, use strftime, use the CAST function to remove leading zeros and the DATE function to extract the date part from a datetime. Specify source name for columns in any join queries. Use the most appropriate columns for each query. Statements should be written in this order: 'SELECT [Columns to Select] FROM [Source Table(s)] WHERE [Conditions if needed] GROUP BY [Columns for Grouping if needed] HAVING [Conditions for Grouping if needed] ORDER BY [Columns for Sorting].'
This prompt grew out of a process of trial and error, which highlights how important it is to have a range of scenarios to test each project against.
Any questions that involved dates tended to throw errors until I modified the prompt to get GPT to handle date-based questions using strftime wherever possible. This method can accept a date in any format and force it into a specific format.
Telling GPT to use the CAST function to remove leading zeros from dates. I needed to do this to pass a Practice SQL exercise, but didn’t know why. So I googled (ChatGPT’d) why we should remove leading zeros, and it’s because it can mess up the order when sorting. So I updated my prompt to remove leading zeros from dates using the CAST function.
Wrap Up 🌯
Woo hoo, that was fun!
This GenAI use-case lets you unlock data insights just by asking questions about your data in plain english. No need for any SQL knowledge, and no more trying to find which spreadsheet or table the data you’re looking for lives in.
There are so many ways you can extend this. You can add a feature to generate questions you can ask to unlock the most business insight based on the table schemas. You can chain this with a SQL database to generate CSV files (the reverse of what we’re doing). Sooo many possibilities!
I’ve shared the entire code you need to implement this yourself as in this open source genai project repository. Or, you can just use the live version 🎁
If you need any help setting this up for your own use-cases, reach out to me on LinkedIn, we can set something up! 😄
Until next time,
Stay sparkly ✨